Download windows 7 for free from this link,
but make sure that it's available for 90 days trial period only.
Following Link contains download link for Windows 7, this link is redirecting to India study channel
Check this link: Windows 7 free trial version for download
Tuesday, December 29, 2009
Sunday, December 27, 2009
advantage of using USB
USB has got many advantage over other type of ports being used in PC's like serial and parallel.
User is having a very good rewarding and productive experience.
Adding peripherals to PC using USB is so easy that anyone can connect. USB has replaced all different kinds of serial and parallel port with just only one type of port that's "USB". No need of add-in Cards, DIP switch settings or don't need to restart PC.
Since most of PC's come with 2 USB ports, so you can connect any extra device using a peripheral USB HUB which have additional ports and let you daisychain multiple device at a time.
Using USB you can have two way communication, which means you can use your PC to control the connected device like synchronizing contacts, media files etc.
User is having a very good rewarding and productive experience.
- Easy to use: It's easy to use, just simply plug-in and start using any device with PC. Simply "Plug and Play". Just connect disconnect and reconnect any device without rebooting PC.
- High Speed: It has speed of around 12Mbits/sec, which is around 100 times faster than serial ports. and with USB 2.0 specifications speed of 480 Mbits/s will be available.
- Expandable: Normally PC's come with 2 or 4 USB ports, which can be extended for use upto 127 ports using USB hubs.
- Reduced Size: Size of USB port is quite small than Serial ports and Parallel Ports.
Adding peripherals to PC using USB is so easy that anyone can connect. USB has replaced all different kinds of serial and parallel port with just only one type of port that's "USB". No need of add-in Cards, DIP switch settings or don't need to restart PC.
Since most of PC's come with 2 USB ports, so you can connect any extra device using a peripheral USB HUB which have additional ports and let you daisychain multiple device at a time.
Using USB you can have two way communication, which means you can use your PC to control the connected device like synchronizing contacts, media files etc.
Wednesday, December 23, 2009
What is COM Port? What is Serial Port? What is relation between COM and serial Port?
COM Port(Communication Port) is the original name given to serial ports on IBM compatible computers.
A serial port is asynchronous port on computer used to connect a serial device to computer capable of transmitting 1 bit at a time. It's basically a I/O port to get the data in and out of using computer. Normally every PC has one or 2 COM ports(serial ports).
A keyboard may be connected to COM1 and some other device may be connected to COM2.
Serial ports were mostly used for communication with RS-232, RS-485 system. A serial port is more than just a port, it converts data from parallel to serial and changes its electrical representation. Inside computer data flows in parallel( using many wires at a time) while serial flow is flow of bits over single wire.
Most of the electronics for serial port (convert parallel data to serial) is done in a computer chip that's known as UART.
Connectors for serial ports are of MALE and FEMALE type.


MALE JACK Female JACK
Reference:
http://www.thaiio.com/serialportinfo.html
A serial port is asynchronous port on computer used to connect a serial device to computer capable of transmitting 1 bit at a time. It's basically a I/O port to get the data in and out of using computer. Normally every PC has one or 2 COM ports(serial ports).
A keyboard may be connected to COM1 and some other device may be connected to COM2.
Serial ports were mostly used for communication with RS-232, RS-485 system. A serial port is more than just a port, it converts data from parallel to serial and changes its electrical representation. Inside computer data flows in parallel( using many wires at a time) while serial flow is flow of bits over single wire.
Most of the electronics for serial port (convert parallel data to serial) is done in a computer chip that's known as UART.
Connectors for serial ports are of MALE and FEMALE type.


MALE JACK Female JACK
Reference:
http://www.thaiio.com/serialportinfo.html
Universal Serial Bus
USB: USB stands for Universal Serial Bus.USB started in late 1990's( around 1996). USB is a hardware interface with defined protocols that enable Host computer to connect to different peripheral devices attached . It connects to a variety of devices like keyboard, mouse, printer, camera, pendrive, external HDD, etc. Hence for many of these kind of devices, USB has become common to have.
Design for USB is standardized by USB Implementers Forum or USB-IF. Currently one Host controller can support at max of 127 device at a time.
Initially when USB was started it was called as 1.0 with data rate of 12 Mbit/s but currently the USB we are using is USB 2.0 with data rate of 480 Mbit/sec. USB 2.0 was started in 2000
Features:
- USB provides Hot plugging and Hot swapping facility, which means you can add or remove peripherals without rebooting your PC or computer(Host controller).
- USB can also supply power to some of the devices which draw small amount of power like Pen Drive, mouse, keyboard.
- speed upto 480 Mbits/sec
- USB 2.0 can have max length of cable up to 5 meters and maximum hubs in series can be only 5.
- Data Cable for USB 2.0 use twisted pair to reduce noise and crosstalk.
- The USB 2.0 specifications provide a 5 V supply on a single wire from which connected USB devices may draw power.
- Devices may be low powered, high powered, or self powered.
To get USB working, you need Hardware and Software:
USb Hardware:
HOST controller/Root HUB
HUB
Device
USB Software:
Device Drivers
Drivers
Controller driver
Physical connection occurs between HOST controller and client bus interface( root hub) USB Host controllers are of following type:
Universal Host Controller Interface(UHCI)
Open Host Controller Interface(OHCI)
Enhanced Host Controller(EHCI)
USB Devices are of three types:
High speed:High speed devices see only high speed transactions, full or low speed devices are accessed via high speed split transactions.
Full Speed: Maximum data rate of 12 Mb/s
Low speed: These are limited in throughput(1.5 Mb/s) and also in feature.
USB connectors are of two types: Type A and type B
Type "A" connector supplies power and "B" receives power. Hence protecting users from connecting same type of connectors, same type of connectors can never be connected. Generally Type "A" connectors are used Host and Type B is used in devices.
Monday, December 21, 2009
Perl Programming
Perl is a programming language which can be used for a large variety of tasks.
Programs written in Perl are called Perl scripts, whereas the term the perl program refers to the system program named perl for executing Perl scripts.
There is a lot to learn in perl, but here I will mention only few items.
Data Types in Perl: scalars, arrays, associative arrays are some of the main data types.
Scalars: are used to store single value, or a string, and they are prefixed with $ sign. Perl doesn't differentiate between integers and floats like C does.
$price=25.6;
$name="Gaurav Gupta"
Array: It is similar to array in C/C++. It's generally called list in perl. It contains many scalar variables in form of list. It is prefixed with @ sign
@name=("gaurav", "kumar", "gupta", "5")
Associative array in perl is called as HASH, it's basically pairs of arrays
Programs written in Perl are called Perl scripts, whereas the term the perl program refers to the system program named perl for executing Perl scripts.
There is a lot to learn in perl, but here I will mention only few items.
Data Types in Perl: scalars, arrays, associative arrays are some of the main data types.
Scalars: are used to store single value, or a string, and they are prefixed with $ sign. Perl doesn't differentiate between integers and floats like C does.
$price=25.6;
$name="Gaurav Gupta"
Array: It is similar to array in C/C++. It's generally called list in perl. It contains many scalar variables in form of list. It is prefixed with @ sign
@name=("gaurav", "kumar", "gupta", "5")
Associative array in perl is called as HASH, it's basically pairs of arrays
Difference between POP and IMAP protocols used for mail clients
POP and IMAP are protocols used at receiving end. POP is older than IMAP and has proved itself but IMAP being newer is also doing great.
POP is called as "POST OFFICE PROTOCOL", it lets you download mails from mail server to your computer or mobile, so that you can access your mail later with any program like outlook express, outlook 2003, windows mail etc... even when there is no internet connection because mails are downloaded to your system. but problem with it is that whenever it connects to server it downloads all mails and deletes contents from server.
IMAP is called as Internet Message Access Protocol(IMAP). It again download mails to your system, which can be accessed later even when you are not connected to net. Whenevr it connects it only reads all the mails on server or download header only, and download only mails which user wants to read.
Now the point comes of difference:
1. The main difference is IMAP keeps constant connection between mail server and mail clients(Computer/mobile). Which means if you perform any action on either system/client or Mail server, it appears on other side too.
Suppose you create a folder "personal" on client side then same folder will also appear on you mail server and vice versa.
Similarly if you move any message from Inbox to other folder in your mail server that will be reproduced in your mail client also. Overall you can say it has better SYNCING method over POP.
2. IMAP has feature of idle mode. Once you login to server you wouldn't be disconnected until you logout, which provides real time notification of mails. While with POP account it only reads mail, and disconnects so you will have to check your Inbox again for new mail.
3.With POP account only mails under ALL MAILs or INBOX are downloaded, not from spam or Deleted mails folder.
4. POP is better when you using for only one system, while IMAP will be better if having multiple systems to access mails.
So overall IMAP is the best way for configuring your mail accounts, because you won't have to worry about maintaining folders over separate places.
IMAP provides better way to access your mailbox from multiple devices, you can check new mails either from computer, mobile, or laptop...
So Finally I will suggest all of you to use IMAP account which is better, simpler, and easy to use for all.
POP is called as "POST OFFICE PROTOCOL", it lets you download mails from mail server to your computer or mobile, so that you can access your mail later with any program like outlook express, outlook 2003, windows mail etc... even when there is no internet connection because mails are downloaded to your system. but problem with it is that whenever it connects to server it downloads all mails and deletes contents from server.
IMAP is called as Internet Message Access Protocol(IMAP). It again download mails to your system, which can be accessed later even when you are not connected to net. Whenevr it connects it only reads all the mails on server or download header only, and download only mails which user wants to read.
Now the point comes of difference:
1. The main difference is IMAP keeps constant connection between mail server and mail clients(Computer/mobile). Which means if you perform any action on either system/client or Mail server, it appears on other side too.
Suppose you create a folder "personal" on client side then same folder will also appear on you mail server and vice versa.
Similarly if you move any message from Inbox to other folder in your mail server that will be reproduced in your mail client also. Overall you can say it has better SYNCING method over POP.
2. IMAP has feature of idle mode. Once you login to server you wouldn't be disconnected until you logout, which provides real time notification of mails. While with POP account it only reads mail, and disconnects so you will have to check your Inbox again for new mail.
3.With POP account only mails under ALL MAILs or INBOX are downloaded, not from spam or Deleted mails folder.
4. POP is better when you using for only one system, while IMAP will be better if having multiple systems to access mails.
So overall IMAP is the best way for configuring your mail accounts, because you won't have to worry about maintaining folders over separate places.
IMAP provides better way to access your mailbox from multiple devices, you can check new mails either from computer, mobile, or laptop...
So Finally I will suggest all of you to use IMAP account which is better, simpler, and easy to use for all.
Thursday, December 17, 2009
Check this link for creation of Gadget
Hi,
Please check this link for learning to develop your own gadget:
http://code.google.com/apis/gadgets/
Gadgets are some simple JAVA script applications which can be embedded on webpages.
Above link contains many other links to other pages which contain information on gadgets.
Please check this link for learning to develop your own gadget:
http://code.google.com/apis/gadgets/
Gadgets are some simple JAVA script applications which can be embedded on webpages.
Above link contains many other links to other pages which contain information on gadgets.
Thursday, December 3, 2009
localtime: How to tell local time in perl
localtime():
It's a function in perl which converts a time as returned by the time function to a 9-element list with the time analyzed for the local time zone. Typically used as follows:
0: sec, 1: min, 2: hour, 3:mDay, 4:mon, 5:year, 6:wDay, 7:yDay, 8:isDst
my $curTime = time();
my ( $sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst) = localtime($curTime);
$year is the number of years from 1900, so for 2009 it will be 109.
so you will have to 1900 in $ year.
$year += 1900;
print "$mday/$mon/$year --- $hour:$min:$sec";
my $ltime = localtime();
print $ltime; It will print as "Thu Dec 3 00:43:57 200"
It's a function in perl which converts a time as returned by the time function to a 9-element list with the time analyzed for the local time zone. Typically used as follows:
0: sec, 1: min, 2: hour, 3:mDay, 4:mon, 5:year, 6:wDay, 7:yDay, 8:isDst
my $curTime = time();
my ( $sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst) = localtime($curTime);
$year is the number of years from 1900, so for 2009 it will be 109.
so you will have to 1900 in $ year.
$year += 1900;
print "$mday/$mon/$year --- $hour:$min:$sec";
my $ltime = localtime();
print $ltime; It will print as "Thu Dec 3 00:43:57 200"
Using mkpath in perl
mkpath (path, bool, perm)
Creates a directory path and returns a list of all directories created. It requires File::Path module
It takes the following arguments:
path: Name of the path or reference to a list of paths to create.
bool : Boolean. If true, mkpath prints the name of each directory as it is created. Default is false.
perm : Numeric mode indicating the permissions to use when creating the directories. Default is 0777.
======================================
$path = "C:\\test" ;
mkpath($path); # it will create the directories required.
print mkpath($path, 1); # it will also print all the directories made during mkpath.
Creates a directory path and returns a list of all directories created. It requires File::Path module
It takes the following arguments:
path: Name of the path or reference to a list of paths to create.
bool : Boolean. If true, mkpath prints the name of each directory as it is created. Default is false.
perm : Numeric mode indicating the permissions to use when creating the directories. Default is 0777.
======================================
$path = "C:\\test" ;
mkpath($path); # it will create the directories required.
print mkpath($path, 1); # it will also print all the directories made during mkpath.
Wednesday, December 2, 2009
Information on Perl
If you want some more information on Perl there is one place where you can find much more on Perl, you can even join communities there on PERL. Indiastudy channel is a site which has got a lot of resources on Perl.
Check following link: http://www.indiastudychannel.com/sites/156782/ViewCommunityMembers.aspx
Check following link: http://www.indiastudychannel.com/sites/156782/ViewCommunityMembers.aspx
Sunday, November 29, 2009
Chrome's New Tab Feature on Firefox
Now you can get Google chrome's new tab feature on your Mozilla Firefox. When you open new tab in firefox, then you will see 9 thumbnails of most frequently visited pages, Recent bookmarks, and recently closed pages. So if you had liked this feature on Chrome, and you use firefox as default, so now you can use this feature on firefox also. To get this feature you need to install Google toolbar 5 for firefox.
This will make your life faster on Firefox, at just only one click you will be able to access your favorite links.
This will make your life faster on Firefox, at just only one click you will be able to access your favorite links.
Friday, November 27, 2009
Automating Internet explorer applicatios with Win32::OLE to open any website
Introdution
Perl has a very good module, for automation in Win32 system, called as Win32::OLE. Everyone uses internet now. There are many place where you may need to fill the forms, which is very tedious job, and it requires a lot of effort and time if form has many data entry points. So you will definitely think of getting this work automated somehow, so that you don't have to fill the complete form. Also there are a lot of e-books available on net for online reading, but there main problem comes how to read e-book if you don't have internet access at any point. I wanted to get all .html pages of any online book saved to my system without doing it manually.
The best solution is to get that book downloaded for you either in html format or .chm or .pdf. All this can be done using Win32::OLE module which will automate the apllication as per your requirement.
Usage:
The first thing is how to start Iexplorer.exe, without clicking on ICON of IE. You can start IE in that way but you won't be able to do anything you want.
So to open IE :
my $IE = WIn32::OLE->new("InternetExplorer.Application") || die "Couldn't open IE\n" ;
It's good but problem was that I was not able to see IExp.So I again read the document and found that there is a property which should be set:
$IE->{visible} = 1;
This time IE will get opened but with blank screen, so to open any web page use following:
In next posts I will tell you how to navigate to links present in that page.
Perl has a very good module, for automation in Win32 system, called as Win32::OLE. Everyone uses internet now. There are many place where you may need to fill the forms, which is very tedious job, and it requires a lot of effort and time if form has many data entry points. So you will definitely think of getting this work automated somehow, so that you don't have to fill the complete form. Also there are a lot of e-books available on net for online reading, but there main problem comes how to read e-book if you don't have internet access at any point. I wanted to get all .html pages of any online book saved to my system without doing it manually.
The best solution is to get that book downloaded for you either in html format or .chm or .pdf. All this can be done using Win32::OLE module which will automate the apllication as per your requirement.
Usage:
The first thing is how to start Iexplorer.exe, without clicking on ICON of IE. You can start IE in that way but you won't be able to do anything you want.
So to open IE :
my $IE = WIn32::OLE->new("InternetExplorer.Application") || die "Couldn't open IE\n" ;
It's good but problem was that I was not able to see IExp.So I again read the document and found that there is a property which should be set:
$IE->{visible} = 1;
This time IE will get opened but with blank screen, so to open any web page use following:
$IE->navigate("www.google.co.in");
FOr more information on how I get to know about navigate(), I installed a program call OLEview.exe.( It's available as part of resource tool kit on microsoft website as freeware) After downloading and installing this package: got to C:\Program Files\Windows Resource Kits\Tools and Run oleviw.exe and you will find InternetExplorer application wihitn "automation" and in that within methods, click on "navigate" so you will find following information:[id(0x00000068), helpstring("Navigates to a URL or file.")].
void Navigate(
[in] BSTR URL,
[in, optional] VARIANT* Flags,
[in, optional] VARIANT* TargetFrameName,
[in, optional] VARIANT* PostData,
[in, optional] VARIANT* Headers);In next posts I will tell you how to navigate to links present in that page.
Thursday, November 26, 2009
Batch Command: Subst
SUBST:
Syntax:
subst d: d:path
subst d: /D
Purpose: Substitutes a virtual drive letter for path designation.
Usage:
subst d: e:\system\path ; will map e:\system\path to virtual drive d:
subst d: /D ; will delete the mapped virtual drive d:
subst ; will show available virtual mapped drives.
Syntax:
subst d: d:path
subst d: /D
Purpose: Substitutes a virtual drive letter for path designation.
Usage:
subst d: e:\system\path ; will map e:\system\path to virtual drive d:
subst d: /D ; will delete the mapped virtual drive d:
subst ; will show available virtual mapped drives.
Monday, November 16, 2009
Finding free space in android mobile from command line
from ur PC's command prompt you can find out the space available in your android mobile. If you have android SDK installed on ur system then you can type following command:
adb shell df
This command will give you total space, available and used space as following:
/dev: 47172K total, 12K used, 47160K available (block size 4096)
/sqlite_stmt_journals: 4096K total, 0K used, 4096K available (block size 4096)
/system: 65536K total, 61216K used, 4320K available (block size 4096)
/data: 65536K total, 32656K used, 32880K available (block size 4096)
/cache: 65536K total, 1156K used, 64380K available (block size 4096)
/sdcard: 522228K total, 1660K used, 520568K available (block size 2048)
If you don't have SDK then directly on ur device terminal you can type "df" and check the space available.
Otherwise there are some tools available as eclipse memory analyzer which will tell you the memory being utilized by programs when they are running, i have'nt used it till now so I don't know much.
adb shell df
This command will give you total space, available and used space as following:
/dev: 47172K total, 12K used, 47160K available (block size 4096)
/sqlite_stmt_journals: 4096K total, 0K used, 4096K available (block size 4096)
/system: 65536K total, 61216K used, 4320K available (block size 4096)
/data: 65536K total, 32656K used, 32880K available (block size 4096)
/cache: 65536K total, 1156K used, 64380K available (block size 4096)
/sdcard: 522228K total, 1660K used, 520568K available (block size 2048)
If you don't have SDK then directly on ur device terminal you can type "df" and check the space available.
Otherwise there are some tools available as eclipse memory analyzer which will tell you the memory being utilized by programs when they are running, i have'nt used it till now so I don't know much.
Thursday, November 12, 2009
How to enable remote connection in your windows XP system
It's used to connect your system remotely from other system for access of data or programs.
control panel->system->remote tab

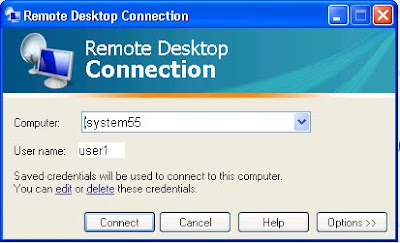
control panel->system->remote tab

Make sure it's "Allow users to connect remotely to this computer" checked as in above picture.
you can see the name of computer to be connected is "system55". you can also add remote users who can use this system.
Now when you click on remote desktop connection under program files->accessibility->remote desktop connection then give the name of computer as "system55" and give user name and password for system.

Thursday, September 3, 2009
Mobile compatible sites,( Wap Sites) for downloading Game, video, wallpapers and ringtones
Following are the websites which I found really good for downloading images, wallpapers, games, ringtones, games, applications and much much more for your mobile....
You can access these sites directly from your mobile.
chakpak(for movie related Info)(m.chakpak.com)
Getjar( for games, and many applications):http://m.getjar.com/mobile/
My tiny phone(for downloading games, walls, ringtones and videos)
Free ringtones( For free ringtones in mp3 format)
wap king
Mobitube(SImilar to youtube for mobile)
You can access these sites directly from your mobile.
chakpak(for movie related Info)(m.chakpak.com)
Getjar( for games, and many applications):http://m.getjar.com/mobile/
My tiny phone(for downloading games, walls, ringtones and videos)
Free ringtones( For free ringtones in mp3 format)
wap king
Mobitube(SImilar to youtube for mobile)
Wednesday, August 26, 2009
Use of shift() function
Shift() function is mostly used to remove and return the first element from an array reduces the the size of array by one. First element in a array is the lowest indexed element.While pop() removes the last element from the array, which is highest indexed.
@mynames = ("larry", "james", "peter");
$firstname = shift(@mynames);
# now $firstname will be "larry" and @mynames will be ("james", "peter").
@mynames = ("larry", "james", "peter");
$firstname = shift(@mynames);
# now $firstname will be "larry" and @mynames will be ("james", "peter").
Monday, August 24, 2009
using 2>&1
It's basically shell command for redirecting the standard error.
1. cat food 2>&1 >file
cat: can't open food2. cat food >file 2>&1
In first command shell sees 2>&1 first and redirects the standard error(file descriptor 2)to same place as standard outpur(file descriptor 1) goes ie STDOUT, while in second command
standard output goes to "file" so Standard Error(2) will also be redirected to same loaction
i.e. to the "file"
Friday, August 21, 2009
Perl regular expressions(RE) - Part1
Perl is used by many people just because of Perl. It gives Perl very powerful capability of matching and substitution operations on text.
Regular expressions uses special characters to match text, which makes it very powerful for Text processing.
OPERATORS:
The Matching Operator : m/PATTERN/cgismxo
Substitution Operator : s/PATTERN/REPLACEMENT/egismxo
transliteration Operator : tr/SEARCHLIST/REPLACEMENTLIST/cds
all above operators generally works on $_
================================================================
Modifiers:
Following modifers are related to interpretation of PATTERN. Modifiers that alter the way a regular expression is used by Perl are detailed in PerlRE quote like operators
modifiers for matching:
/i : Ignore alphabetical case(case insens
/m : let ^ and $ match next to embedded \n.
/s : Let . match newline and ignore deprecated $*.
/x : Ignores white space and permit comments in patterns.
/o : to substitute variable only once and it will compile pattern only once .
/g : Globally find all matches, within a string all matches are searched for matching operator.
/gc : Global matching and keep current position after failed match, because failed match or change in target string resets the position, so to avoid, use this modifier.For further explanation refer to using regular expression in perlre tutorial
In substitution operation //c is not used instead //e.
/e : Evaluates right side as expression.
Transliteration Modifier:
/c : Complement SEARCHLIST.(character set in SEARCHLIST complemented so effective list will contain charcters not present in SEARCHLIST)
/d : Delete found but unreplaced characters(Any character specified in SEARCHLIST but not given a replacement in REPLACEMENTLIST are deleted).
/s : Squash duplicate replaced characters( sequences of characters converted to the same character are squashed down to a single instance of the character)
Use of transliteration:
Converting from uppercase to lower case.
$tag = "This is My BLOG";
$tag_c = $tag;
$tag_c =~ tr/A-Z/a-z/; #prints "this is my blog"
$count = ($tag =~ tr/A-Z//); # counts the capital characters in $tag.
$count = ($tag =~ tr/A-Za-z//); # counts all the characters in $tag.
$count = ($tag =~ tr/aeiouAEIOU//); # counts all the vowels in $tag.
================================================================
=~ and =! are called binding operator
=~ means True if pattern matches and
=! means True if pattern doesn't match.
These are used when you want to use m// or s/// or tr/// to operate on other than $_, so the string to be serached is bound with binding operator.
===============================================================
Some useful links for regular expressions:
RegExpression Full Tutorial in Perldoc
Regular expressions quick tutorial in Perldoc
Regular Expressions (a tutorial)
http://www.troubleshooters.com/codecorn/littperl/perlreg.htm
Regular expressions uses special characters to match text, which makes it very powerful for Text processing.
OPERATORS:
The Matching Operator : m/PATTERN/cgismxo
Substitution Operator : s/PATTERN/REPLACEMENT/egismxo
transliteration Operator : tr/SEARCHLIST/REPLACEMENTLIST/cds
all above operators generally works on $_
================================================================
Modifiers:
Following modifers are related to interpretation of PATTERN. Modifiers that alter the way a regular expression is used by Perl are detailed in PerlRE quote like operators
modifiers for matching:
/i : Ignore alphabetical case(case insens
/m : let ^ and $ match next to embedded \n.
/s : Let . match newline and ignore deprecated $*.
/x : Ignores white space and permit comments in patterns.
/o : to substitute variable only once and it will compile pattern only once .
/g : Globally find all matches, within a string all matches are searched for matching operator.
/gc : Global matching and keep current position after failed match, because failed match or change in target string resets the position, so to avoid, use this modifier.For further explanation refer to using regular expression in perlre tutorial
In substitution operation //c is not used instead //e.
/e : Evaluates right side as expression.
Transliteration Modifier:
/c : Complement SEARCHLIST.(character set in SEARCHLIST complemented so effective list will contain charcters not present in SEARCHLIST)
/d : Delete found but unreplaced characters(Any character specified in SEARCHLIST but not given a replacement in REPLACEMENTLIST are deleted).
/s : Squash duplicate replaced characters( sequences of characters converted to the same character are squashed down to a single instance of the character)
$word =~ tr/a-zA-Z//s; # bookkeeper -> bokeper====================================================================
Use of transliteration:
Converting from uppercase to lower case.
$tag = "This is My BLOG";
$tag_c = $tag;
$tag_c =~ tr/A-Z/a-z/; #prints "this is my blog"
$count = ($tag =~ tr/A-Z//); # counts the capital characters in $tag.
$count = ($tag =~ tr/A-Za-z//); # counts all the characters in $tag.
$count = ($tag =~ tr/aeiouAEIOU//); # counts all the vowels in $tag.
================================================================
=~ and =! are called binding operator
=~ means True if pattern matches and
=! means True if pattern doesn't match.
These are used when you want to use m// or s/// or tr/// to operate on other than $_, so the string to be serached is bound with binding operator.
===============================================================
Some useful links for regular expressions:
RegExpression Full Tutorial in Perldoc
Regular expressions quick tutorial in Perldoc
Regular Expressions (a tutorial)
http://www.troubleshooters.com/codecorn/littperl/perlreg.htm
Monday, August 10, 2009
Use of quote like operators
Various "q" type of functions are mentioned below
q// or q{} :
It represents single-quoted, literal string. It can be used instead of single quotes( ' '). Here // or {} are delimiters.
qq/ / or qq{ } :
It represents Double-quoted interpolated string. It can be used instead of single quotes( '" ").
e.g.
my $blog = "www.batchandperl.blogspot.com";
print q{ This is my blog: $blog \n}; # prints "This is my blog: $blog \n"
print qq{ This is my blog: $blog \n}; # prints "This is my blog: www.batchandperl.blogspot.com"
qr/STRING/msixpo or qr{ }msixpo :
This operator quotes it's string as regular expression. STRING will be interpolated in the same way as PATTERN in m/PATTERN/. If "'" is used as the delimiter, no interpolation is done. It Returns a Perl value which may be used instead of the corresponding
e.g.
$rex = qr/my.STRING/is;
s/$rex/foo/;
is equivalent to
s/my.STRING/foo/is;
$re = qr/$pattern/;
$string =~ /foo${re}bar/; # can be interpolated in other patterns
$string =~ $re; # or used standalone
$string =~ /$re/; # or this way
Options for using qr// are:
It's an alternative to using back quotes to execute system commands. It's equivalent to ( ` ` ).
e.g.
my @dir_out = qx{dir};
print @dir; #prints returned value by executing `dir` command on shell.
qw/STRING / or qw{};
It's a quick way to specify multiple single quoted words present in STRING and delimited by white space. Simply you can use qw() to create an array. It returns a list consisting of elements of LIST as they were single quoted.
It's equivalent to
q// or q{} :
It represents single-quoted, literal string. It can be used instead of single quotes( ' '). Here // or {} are delimiters.
qq/ / or qq{ } :
It represents Double-quoted interpolated string. It can be used instead of single quotes( '" ").
e.g.
my $blog = "www.batchandperl.blogspot.com";
print q{ This is my blog: $blog \n}; # prints "This is my blog: $blog \n"
print qq{ This is my blog: $blog \n}; # prints "This is my blog: www.batchandperl.blogspot.com"
qr/STRING/msixpo or qr{ }msixpo :
This operator quotes it's string as regular expression. STRING will be interpolated in the same way as PATTERN in m/PATTERN/. If "'" is used as the delimiter, no interpolation is done. It Returns a Perl value which may be used instead of the corresponding
/STRING/msixpo expression.e.g.
$rex = qr/my.STRING/is;
s/$rex/foo/;
is equivalent to
s/my.STRING/foo/is;
$re = qr/$pattern/;
$string =~ /foo${re}bar/; # can be interpolated in other patterns
$string =~ $re; # or used standalone
$string =~ /$re/; # or this way
Options for using qr// are:
- m Treat string as multiple lines.
- s Treat string as single line. (Make . match a newline)
- i Do case-insensitive pattern matching.
- x Use extended regular expressions.
- p When matching preserve a copy of the matched string so
- that ${^PREMATCH}, ${^MATCH}, ${^POSTMATCH} will be defined.
- o Compile pattern only once.
If a precompiled pattern is embedded in a larger pattern then the effect of 'msixp' will be propagated appropriately. The effect of the 'o' modifier has is not propagated, being restricted to those patterns explicitly using it.
It's an alternative to using back quotes to execute system commands. It's equivalent to ( ` ` ).
e.g.
my @dir_out = qx{dir};
print @dir; #prints returned value by executing `dir` command on shell.
qw/STRING / or qw{};
It's a quick way to specify multiple single quoted words present in STRING and delimited by white space. Simply you can use qw() to create an array. It returns a list consisting of elements of LIST as they were single quoted.
It's equivalent to
split(' ', q/STRING/);
e.g.
qw(foo bar baz); is equivalent to ('foo', 'bar', 'baz')
A very common mistake in STRING is to try to separate words with comma or to put comments
into multi-line qw() string. For this, pragma use warnings ; produces warnings.
quotemeta EXPR:
It returns a string with all meta characters escaped.
For example, quotemeta("AB*..C") returns "AB\*\.\.C".
print quotemeta("AB*\n[.]*");
#returns
AB\*\
\[\.\]\*
Friday, August 7, 2009
Links for websites for different types of programming
Documentation of all types of book (really good one){contains: Internet, Perl and other scripting languages, Web designing and publishing, JAVA, Data Bases, Image processing, Networking, Unix related, Net ware, Microsoft Products, etc.. }
O'Reilly CD BOOKSHELF (Books for JAVA, Perl, UNIX,Networking, Web Developer,Oracle, XML,etc....)
Web Programming Desktop Referencing (A book from above documentation link link)
Quick Reference Guides ( Quick reference guides for Perl's regular exp, special variables, and VI editor)
O'Reilly CD BOOKSHELF (Books for JAVA, Perl, UNIX,Networking, Web Developer,Oracle, XML,etc....)
Web Programming Desktop Referencing (A book from above documentation link link)
Quick Reference Guides ( Quick reference guides for Perl's regular exp, special variables, and VI editor)
Special Variables
To know more about special variables see Perl documentation:
C:\>perldoc perlvar
There are some pre-defined in Perl which have special meaning to Perl. They also have some analogous names to them, to use long variable name you need to say in script:
use English;
$_ : [$ARG]
The default input and pattern-searching space. In following places by default Perl will take $_ as argument. It's a global variable.
* print() and unlink functions.
* pattern matching operations s///, m//, tr/// when used without =~ operator
* default iterator variable in foreach(), if no variable supplied.
@ARGV
It's a array which stores all the command line arguments, with which the Perl program was called.
$(digits):
contains sub pattern matched with corresponding set of capturing parenthesis in last successful pattern match. These all variables are read only and dynamically scoped within the scope of that block.
e.g. m/^(ram:)(\w+ \.)(\d+)/;
In above match $1 will contains"ram:" and $2 contains any alphanumeric character ending with"." and $3 contains and digit character after that.
IO::Handle->input_record_separator(EXPR)
$INPUT_RECORD_SEPARATOR
$RS
$/ : (Global)
It actually splits the input file into records depending upon the value set to it, by default it's newline, so file will be split into lines. This influence Perl's idea of what a "line" is. It should be declared as "local" within any block to make it effective in that block only, otherwise it will remain set till the end of Perl program.
local $/; # Read the whole file in at once
$/ = undef; # Read the whole file in at once
undef $/; # same as above
$/ = ""; # Read in paragraph by paragraph
$/ = "\n%\n"; # Read in Unix fortunes
open(my $fh, "<", $fortunes) or die $!;
while(<$fh>) {
chomp; # remove \n%\n
}
local $/ = undef;
open my $fh, "abc.txt" or die $!;
$_ = <$fh>; #whole file is now in $_
}
It is a compile-time error to try and declare a special variable using my.
For more information on Perl's special variables one can refer to any of the following links:
Perl 5 by Example: Using Special variables
Perl Special Variables: chapter 8
Perl In a nutshell: chapter 4
Perl Predefined Names
Perl-Special variables
C:\>perldoc perlvar
There are some pre-defined in Perl which have special meaning to Perl. They also have some analogous names to them, to use long variable name you need to say in script:
use English;
$_ : [$ARG]
The default input and pattern-searching space. In following places by default Perl will take $_ as argument. It's a global variable.
* print() and unlink functions.
* pattern matching operations s///, m//, tr/// when used without =~ operator
* default iterator variable in foreach(), if no variable supplied.
@ARGV
It's a array which stores all the command line arguments, with which the Perl program was called.
$(digits)
contains sub pattern matched with corresponding set of capturing parenthesis in last successful pattern match. These all variables are read only and dynamically scoped within the scope of that block.
e.g. m/^(ram:)(\w+ \.)(\d+)/;
In above match $1 will contains"ram:" and $2 contains any alphanumeric character ending with"." and $3 contains and digit character after that.
IO::Handle->input_record_separator(EXPR)
$INPUT_RECORD_SEPARATOR
$RS
$/ : (Global)
It actually splits the input file into records depending upon the value set to it, by default it's newline, so file will be split into lines. This influence Perl's idea of what a "line" is. It should be declared as "local" within any block to make it effective in that block only, otherwise it will remain set till the end of Perl program.
local $/; # Read the whole file in at once
$/ = undef; # Read the whole file in at once
undef $/; # same as above
$/ = ""; # Read in paragraph by paragraph
$/ = "\n%\n"; # Read in Unix fortunes
open(my $fh, "<", $fortunes) or die $!;
while(<$fh>) {
chomp; # remove \n%\n
}
- We always think that chomp remove newline, it's because $/ is set to newline by default, So changing it's value will also change the way chomp works
- $/ also changes the way read line(<>) works.
local $/ = undef;
open my $fh, "abc.txt" or die $!;
$_ = <$fh>; #whole file is now in $_
}
It is a compile-time error to try and declare a special variable using my.
For more information on Perl's special variables one can refer to any of the following links:
Perl 5 by Example: Using Special variables
Perl Special Variables: chapter 8
Perl In a nutshell: chapter 4
Perl Predefined Names
Perl-Special variables
Array and Hash
my @aray = ( 12, 13, 87, 238, 28, 761);
my $last_index = $#array; # it will be wrong if typed like #$aray, because it will comment out $array.
my $length = @array; # it's similar to typecasting, In this way we treating an array like a scalar
print "last index = ",$last_index,"\n"; #prints: 5
print "length of array = $length\n"; #prints: 6
print "second lat element of array = $array[-2] \n"; # prints: 28
print "fifth element = $array[4] \n"; #prints: 28
Hashes:
my %ageof = {
ram => 23,
shyam => 25,
rita => 30,
sita => 16,
};
my %fav_color = {
ram => "blue",
shyam => "white",
rita => "orange",
sita => "red",
};
"=>" is called as fat comma, it behaves same as normal comma(only it's bigger so easy to see), and it automatically quotes values to it's left, but values on right need to be quoted.
Hash Lookup:
print $ageof{shyam}; # prints 25
print $fav_color{rita}; # prints: orange
Adding Hah Pairs:
$ageof{mohan} = 47; # now mohan is added into hash %ageof;
Hash Size:
my $num_of_pairs = keys(%ageof);
Hashes don't Interpolate in quotes.
Arrays and Hashes shouldn't be passed to subroutines directly because it leads them to lost their identity, So they should be passed as reference.
if( greater_length( @array1, @array2 ) ) {
# .........
}
sub greater_length {
my ( @array1, @array2 ) = @_;
# @array1 now has "all" of the elements and @array2 is "empty"
return @array1 > @array2; # Always true!
}
# by using reference above problem can be solved
if( greater_length( \@array1, \@array2 ) ) {
# ........
}
sub greater_length {
my ( $array1, $array2 ) = @_;
my @array1 = @$array1;
my @array2 = @$array2;
return @array1 > @array2;
}
my $last_index = $#array; # it will be wrong if typed like #$aray, because it will comment out $array.
my $length = @array; # it's similar to typecasting, In this way we treating an array like a scalar
print "last index = ",$last_index,"\n"; #prints: 5
print "length of array = $length\n"; #prints: 6
print "second lat element of array = $array[-2] \n"; # prints: 28
print "fifth element = $array[4] \n"; #prints: 28
Hashes:
my %ageof = {
ram => 23,
shyam => 25,
rita => 30,
sita => 16,
};
my %fav_color = {
ram => "blue",
shyam => "white",
rita => "orange",
sita => "red",
};
"=>" is called as fat comma, it behaves same as normal comma(only it's bigger so easy to see), and it automatically quotes values to it's left, but values on right need to be quoted.
Hash Lookup:
print $ageof{shyam}; # prints 25
print $fav_color{rita}; # prints: orange
Adding Hah Pairs:
$ageof{mohan} = 47; # now mohan is added into hash %ageof;
Hash Size:
my $num_of_pairs = keys(%ageof);
Hashes don't Interpolate in quotes.
Arrays and Hashes shouldn't be passed to subroutines directly because it leads them to lost their identity, So they should be passed as reference.
if( greater_length( @array1, @array2 ) ) {
# .........
}
sub greater_length {
my ( @array1, @array2 ) = @_;
# @array1 now has "all" of the elements and @array2 is "empty"
return @array1 > @array2; # Always true!
}
# by using reference above problem can be solved
if( greater_length( \@array1, \@array2 ) ) {
# ........
}
sub greater_length {
my ( $array1, $array2 ) = @_;
my @array1 = @$array1;
my @array2 = @$array2;
return @array1 > @array2;
}
Monday, August 3, 2009
Quotes and interpolation
Perl has two kinds of qoutes to delimit the strings, double(" ") and single (' ').
my $fruit = "apple";
my $fruit ='apple' ;
but there is one difference that double quotes interpolate, while single quote doesn't. Interpolation allows to have variables inside double quotes and have those variables replaced with their content.
e.g.
print " my favorite fruit is $fruit \n"; #prints: my favorite fruit is apple
print ' my favorite fruit is $fruit \n'; # prints: my favorite fruit is $fruit
But exception is HASH which don't get interpolated within double quotes.
some special characters also can be interpolated within double quotes like \n, \t, \b ....while in case of single quotes these are merely pair of characters.
escape character(\) can be used to escape some characters within quotes like \\, \', \"
to avoid use of \ you can use qq{} instead of " " and q{} instead of ' '
my $fruit = "apple";
my $fruit ='apple' ;
but there is one difference that double quotes interpolate, while single quote doesn't. Interpolation allows to have variables inside double quotes and have those variables replaced with their content.
e.g.
print " my favorite fruit is $fruit \n"; #prints: my favorite fruit is apple
print ' my favorite fruit is $fruit \n'; # prints: my favorite fruit is $fruit
But exception is HASH which don't get interpolated within double quotes.
some special characters also can be interpolated within double quotes like \n, \t, \b ....while in case of single quotes these are merely pair of characters.
escape character(\) can be used to escape some characters within quotes like \\, \', \"
to avoid use of \ you can use qq{} instead of " " and q{} instead of ' '
Using Warnings
It's always good to have warnings enabled, so that u can get to know that u are doing something wrong. It's always worth spending some time wondering why?
A few things that trigger warning:
A few things that trigger warning:
- Trying to read from or write to an unopened filehandle, socket or device.
- Treating a string of non-numeric characters as if it were a number.
- Printing or performing comparisons with undefined values.
- Assigning an odd number of elements to a hash (collection of key-value pairs).
using strict
STRICT:-
It ensures that you pre-declare your variables, don;t have barewords and don;t use symbolic references. It also saves from making accidental spelling mistakes:
#without strict;
$num_friend = 2;
print " I have $num_friends \n"; #oops wrong spelling
if you have used strict then case will die with error
Global symbol "$num_friends" requires explicit package name.
use strict;
use warnings;
sub say_hi {
my $first = shift;
my $name = shift;
print $first, $name, "\n";
return;
}
&say_hi("hi", "gkg");
But you should be aware that there are more than one way of calling a subroutine. In this case since we have already defined the subroutine so we don't need to prefaec it with &, and it can also be called as
say_hi("hi", "GKG."); #valid but not a correct way.
here you can also call it as:
say_hi "hi" , "GKG" ; #valid, but not a good way of coding
say_hi ; #valid, just prints new line character, no params in, just a bareword
while above command can be written in more readable way as :
&say_hi();
but there are some commands where parentheses are invalid:
#Valid syntax
print OUTPUT_FH $message, $name,"\n";
#Invalid Syntax
print(OUTPUT_FILE $message, $name, "\n");
parentheses indicates a list for print and needs comma between each paarmeter
#Okay but weird
print OUTPUT_FILE ($message, $name, "\n");
>>Use qoutes for strings.
>>Always call your subroutines with & and (), even if there are no args.
but when you are using "qw" then there is no need to have qoutes for variables inside a list.
Symbolic references:
the variable $var indicates that $var is a reference variable,and it is expected that the value will be returned to the variable referenced by $var when reference was taken. But if $var is not a refernce variable at all? then Perl tries to check whether it contains any string, if yes then perl mess around with this string.
$x = 0;
$var = "x";
$$var = 30; # Modifies $x to 30 , because $var is a symbolic reference !
so to avoid this situation you can use
use strict 'refs'; # Tell Perl not to allow symbolic references
$var = "x";
$$var = 30;
Strict refs will remain activated tillthe end of block, but it can be deactivated by saying,
no strict; # or
no strict 'refs';
for more on symbolic references refer to chapter 8.4 "Programming Perl" 3rd edition, O'relly.
or perldoc perlref .
It ensures that you pre-declare your variables, don;t have barewords and don;t use symbolic references. It also saves from making accidental spelling mistakes:
#without strict;
$num_friend = 2;
print " I have $num_friends \n"; #oops wrong spelling
if you have used strict then case will die with error
Global symbol "$num_friends" requires explicit package name.
A bareword is any combination of letters, numbers, and underscores, and is not qualified by any symbols. That is, while $apple is a scalar and @apple is an array, while apple is a bareword.
use strict;
use warnings;
sub say_hi {
my $first = shift;
my $name = shift;
print $first, $name, "\n";
return;
}
&say_hi("hi", "gkg");
But you should be aware that there are more than one way of calling a subroutine. In this case since we have already defined the subroutine so we don't need to prefaec it with &, and it can also be called as
say_hi("hi", "GKG."); #valid but not a correct way.
here you can also call it as:
say_hi "hi" , "GKG" ; #valid, but not a good way of coding
say_hi ; #valid, just prints new line character, no params in, just a bareword
while above command can be written in more readable way as :
&say_hi();
but there are some commands where parentheses are invalid:
#Valid syntax
print OUTPUT_FH $message, $name,"\n";
#Invalid Syntax
print(OUTPUT_FILE $message, $name, "\n");
parentheses indicates a list for print and needs comma between each paarmeter
#Okay but weird
print OUTPUT_FILE ($message, $name, "\n");
>>Use qoutes for strings.
>>Always call your subroutines with & and (), even if there are no args.
but when you are using "qw" then there is no need to have qoutes for variables inside a list.
Symbolic references:
the variable $var indicates that $var is a reference variable,and it is expected that the value will be returned to the variable referenced by $var when reference was taken. But if $var is not a refernce variable at all? then Perl tries to check whether it contains any string, if yes then perl mess around with this string.
$x = 0;
$var = "x";
$$var = 30; # Modifies $x to 30 , because $var is a symbolic reference !
so to avoid this situation you can use
use strict 'refs'; # Tell Perl not to allow symbolic references
$var = "x";
$$var = 30;
Strict refs will remain activated tillthe end of block, but it can be deactivated by saying,
no strict; # or
no strict 'refs';
for more on symbolic references refer to chapter 8.4 "Programming Perl" 3rd edition, O'relly.
or perldoc perlref .
Using Perl Documentation
There is lot of information on Perl documented as Perl documentation, to use this documentation you can type "perldoc" and some tags with it.
To get the info about these tags just type "perldoc perl" you will get all the commands which you can give.
some of the important commands which can be used to explore more in perldoc are as following:
perldoc perldoc: Instructions on using perldoc
perldoc perl :to get the overview of Perl documentation
perldoc perlintro : Perl Introduction for beginners
perldoc perltoc: Table of contents
perldoc perlfunc : full list of all functions
perldoc -f : Help with specific function
perldoc perlmodlib : List of all modules installed
perldoc perllocal : locally installed modules
Tutorials: perldoc _ _ _ _
perlreftut: Perl references
perlretut: Perl Regular Expressions
perlboot: perl object oriented tutorial for beginners
perlbot: some OO tricks and examples
perldebtut: debugging tutorial
perlfaq: Frequently asked questions
perlopentut : perl open() tutorial
perlbook & perlfaq2 : gives info about perl books
For reference manuals: perldoc_ _ _ _
perldata : perl data structures,
perlop : perl operators and precedence,
perlre : perl regular expressions,
To get the info about these tags just type "perldoc perl" you will get all the commands which you can give.
some of the important commands which can be used to explore more in perldoc are as following:
perldoc perldoc: Instructions on using perldoc
perldoc perl :to get the overview of Perl documentation
perldoc perlintro : Perl Introduction for beginners
perldoc perltoc: Table of contents
perldoc perlfunc : full list of all functions
perldoc -f
perldoc perlmodlib : List of all modules installed
perldoc perllocal : locally installed modules
Tutorials: perldoc _ _ _ _
perlreftut: Perl references
perlretut: Perl Regular Expressions
perlboot: perl object oriented tutorial for beginners
perlbot: some OO tricks and examples
perldebtut: debugging tutorial
perlfaq: Frequently asked questions
perlopentut : perl open() tutorial
perlbook & perlfaq2 : gives info about perl books
For reference manuals: perldoc_ _ _ _
perldata : perl data structures,
perlop : perl operators and precedence,
perlre : perl regular expressions,
Thursday, July 30, 2009
Running any process in background from perl script
If you want to run any process in background from your perl script as follows:
system("start [process]");
By using the above command, a new command window will get opened and the process will start running on that command window and control will return to your perl script from where you called this command, so the very next command can also be executed.
But if you use system("[process]"); then it will run on same command window and control will come back once the process is completed.
e.g.
system("start tail -f abc.txt");
print("Tail command is running in background\n");
will call a new command window and "tail -f " command will be executed in that and then print command will get called.
system("start [process]");
By using the above command, a new command window will get opened and the process will start running on that command window and control will return to your perl script from where you called this command, so the very next command can also be executed.
But if you use system("[process]"); then it will run on same command window and control will come back once the process is completed.
e.g.
system("start tail -f abc.txt");
print("Tail command is running in background\n");
will call a new command window and "tail -f " command will be executed in that and then print command will get called.
Tuesday, July 28, 2009
Perl Debugger Commands
C:\> perl -d xyz.pl
{Debugging Mode starts}
---> Type n to goto next line.
---> Type q to stop debugging .
---> b [x]: sets breakpoint @ x line
---> d [x]: to get rid of break point @ x line.
---> L : to examine breakpoints set in code
---> s : to step into any function @ any particular line.
---> Type h q for help on q command during debugging.
---> Type h R for help on R command during debugging( to restart the debugging )
---> Type h h for more help during debugging.
main::(book:3): my @books=( 'xyz', 'abc');
DB<1> n <--- command for "next" instruction main::(book:5): print @books;
DB<5> b 20
DB<6> L
DB<7> d 20
{Debugging Mode starts}
---> Type n to goto next line.
---> Type q to stop debugging .
---> b [x]: sets breakpoint @ x line
---> d [x]: to get rid of break point @ x line.
---> L : to examine breakpoints set in code
---> s : to step into any function @ any particular line.
---> Type h q for help on q command during debugging.
---> Type h R for help on R command during debugging( to restart the debugging )
---> Type h h for more help during debugging.
main::(book:3): my @books=( 'xyz', 'abc');
DB<1> n <--- command for "next" instruction main::(book:5): print @books;
DB<5> b 20
DB<6> L
DB<7> d 20
Perl Switches( CLO's)
>>perl -h for getting the help on command line options.
>>perl -v for getting the version of installed perl.
Usage
c:\>perl [switches] [Perl programfile] [Input arguments]
Switches to Perl Interpreter:-
Some important ones:
-w : Turn on many useful warnings( Use always, good for beginners)(RECOMMENDED)
-W : enable all warnings
-c : check syntax without actually executing the perl script.
-d : run script using perl debugger, to debug your script.
Some extra Switches:
-a : autosplit mode with -n or -p (splits $_ into @F)
-e : one line of program (several -e's allowed, omit programfile)
-E : like -e, but enables all optional features
-F/pattern/ : split() pattern for -a switch (//'s are optional)
-n : assume "while (<>) { ... }" loop around program
-p : assume loop like -n but print line also.
-P : run program through C preprocessor before compilation
-X : disable all warnings
Perl One Liners
>> perl -e [any perl instruction(statement) ]
*********************************************************************************
Examples:-
C:\> perl -e "print 'Hello World';" -e "print 'Howzit goin?';"
C:\> Hello WorldHowzit goin?
C:\> perl -n -e 's/^\s+//g; print $_;' file1
Above code is equivalent to
while(<>) {
s/^\s+//g;
print $_;
}
*************************************************
C:\>perl -p -e 's/\r//g' file1 > file1
above usage is a wrong way to write into file which is opened in reading mode, correct way will be as following:
C:\>perl -p -e 's/\r//g' file1 > file2
C:\>rename file2 file1
*************************************************
Note: Multiple -e statements can be used
>>perl -v for getting the version of installed perl.
Usage
c:\>perl [switches] [Perl programfile] [Input arguments]
Switches to Perl Interpreter:-
Some important ones:
-w : Turn on many useful warnings( Use always, good for beginners)(RECOMMENDED)
-W : enable all warnings
-c : check syntax without actually executing the perl script.
-d : run script using perl debugger, to debug your script.
Some extra Switches:
-a : autosplit mode with -n or -p (splits $_ into @F)
-e : one line of program (several -e's allowed, omit programfile)
-E : like -e, but enables all optional features
-F/pattern/ : split() pattern for -a switch (//'s are optional)
-n : assume "while (<>) { ... }" loop around program
-p : assume loop like -n but print line also.
-P : run program through C preprocessor before compilation
-X : disable all warnings
Perl One Liners
>> perl -e [any perl instruction(statement) ]
*********************************************************************************
Examples:-
C:\> perl -e "print 'Hello World';" -e "print 'Howzit goin?';"
C:\> Hello WorldHowzit goin?
C:\> perl -n -e 's/^\s+//g; print $_;' file1
Above code is equivalent to
while(<>) {
s/^\s+//g;
print $_;
}
*************************************************
C:\>perl -p -e 's/\r//g' file1 > file1
above usage is a wrong way to write into file which is opened in reading mode, correct way will be as following:
C:\>perl -p -e 's/\r//g' file1 > file2
C:\>rename file2 file1
*************************************************
Note: Multiple -e statements can be used
Wednesday, July 22, 2009
Links for websites containing Perl related Info
The Perl CD BOOKSHELF (Ver 3.0)(O'Reilly) : (Latest Books)(Most of the O'Reilly Books for Perl are available for online reading)
The Perl CD BOOKSHELF (Ver 1.0)(O'Reilly) (Most of the O'Reilly Books for Perl are available for online reading)
Perl Doc Site (Perl Documentation Web Site)
Perl 5 Wiki ( Perl foundation Site)
Perl Online Books:(Single Book)
Perl For System Administration(1st edition)(O'Reilly) (Available in ver 2.0 of CD Bookshelf)
Fundamentals Of Perl( A online book)(Many Examples are given)
Perl Interview questions (Some Important questions which can be asked in interview)
Perl Training: (Some very good notes for Perl are available here)
Linux topia Picking Up Perl (Some information is available on Perl)
Perl Tutorials:
Perl Tutorial(Steve Cook) (Not for beginners)
PERL5 TUTORIAL( a pdf) (published in 2003)
PERL TUTORIAL POINT
Perl Tutorial(outdated): http://www.tizag.com/perlT/index.php
Perl Blogs:
Practical Perl blog (It's just a blog, so one may find some kind of information)
A Perl Blog
The Perl CD BOOKSHELF (Ver 1.0)(O'Reilly) (Most of the O'Reilly Books for Perl are available for online reading)
Perl Doc Site (Perl Documentation Web Site)
Perl 5 Wiki ( Perl foundation Site)
Perl Online Books:(Single Book)
Perl For System Administration(1st edition)(O'Reilly) (Available in ver 2.0 of CD Bookshelf)
Fundamentals Of Perl( A online book)(Many Examples are given)
Perl Interview questions (Some Important questions which can be asked in interview)
Perl Training: (Some very good notes for Perl are available here)
Linux topia Picking Up Perl (Some information is available on Perl)
Perl Tutorials:
Perl Tutorial(Steve Cook) (Not for beginners)
PERL5 TUTORIAL( a pdf) (published in 2003)
PERL TUTORIAL POINT
Perl Tutorial(outdated): http://www.tizag.com/perlT/index.php
Perl Blogs:
Practical Perl blog (It's just a blog, so one may find some kind of information)
A Perl Blog
Difference between our and my in perl
How does 'our' differ from 'my' and what does 'our' do.
In Summary:
Available since Perl 5, 'my' is a way to declare:
* non-package variables, that are
* private,
* new,
* non-global variables,
* separate from any package; so that the variable
* cannot be accessed in the form of $package_name::variable.
On the other hand, 'our' variables are:
* package variables, and thus automatically
* global variables,
* definitely not private,
* nor are they necessarily new; and they
* can be accessed outside the package (or lexical scope) with the qualified namespace, as $package_name::variable.
Declaring a variable with 'our' allows you to predeclare variables in order to use them under "use strict" without getting typo warnings or compile-time errors. Since Perl 5.6, it has replaced the obsolete 'use vars', which was only file-scoped, and not lexically scoped as is 'our'.
For example, the formal, qualified name for variable $x inside package main is $main::x. Declaring 'our $x' allows you to use the bare $x variable without penalty (i.e., without a resulting error), in the scope of the declaration, when the script uses 'use strict' or 'use strict "vars"'. The scope might be one, or two, or more packages, or one small block.
===================================================================================
The PerlMonks and PerlDoc links from cartman and Olafur are a great reference - below is my crack at a summary:
my variables are lexically scoped within a single block defined by {} or within the same file if not in {}s. They are not accessible from packages/subroutines defined outside of the same lexical scope / block.
our variables are scoped within a package/file and accessible from any code that uses/requires that package/file - name conflicts are resolved between packages by prepending the appropriate namespace.
Just to round it out, local variables are "dynamically" scoped, differing from my variables in that they are also accessible from subroutines called within the same block.
==================================================================================
Coping with scooping(Namespaces)
is a document which has a good overview of Perl scoping rules, but it's old enough to have discussion about "our".
=================================================================================
perldoc is also a good reference.
=================================================================================
one can also refer to page for more reference.
=================================================================================
Perl has two kinds of variables. The first kind are global variables (also
called "package" variables or "symbol table" variables). These variables a)
have a name in a package's symbol table, and b) have a lifetime equal to the
duration of your process (Notwithstanding Perl's "local" statement, which
adds a twist. But save that for another discussion.)
You refer to a package variable like this:
$MyPackage::foo = 1;
This assigns to a scalar, $foo, in the "MyPackage" package. You don't have
to declare such a variable; it is created automatically simply by your
having used it's name.
Perl has a "package" statement, which allows you to define a default package
to be used when you don't explicitly specify one. So the following is
equivalent to what's above:
package MyPackage;
$foo = 1;
(If no package statement has been issued, the default package is "main").
But that raises a problem. Since global variables are created automatically,
it's easy to introduce bugs into your program by making typos in variable
names.
That's where "use strict" comes in. "use strict" (which should *always* be
used in your programs), requires you to pre-declare package variables that
you plan to use without a package name. Consider:
package MyPackage;
use strict;
$foo = 1; # compile-time error: $foo not defined
"our" is a declaration that introduces a package variable. So instead you
write:
package MyPackage;
use strict;
our $foo;
$foo = 1; # OK; $foo has been declared
You can combine the declaration and assignment in one step:
our $foo = 1;
Now if you accidentally misspell $foo as $fooo later in your program, Perl
will raise a compile-time error.
You can think of "our" as a license to use the variable without its package
name under "use strict".
"our" obeys lexical scoping rules. That is to say, your "license" is good
from the point you issue the "our", until the end of the innermost enclosing
block, eval, or file. Consider:
use strict;
{
our $foo;
$foo = 1; # OK, "our" declaration is in force
} # block ends, "our" declaration ends
$foo = 2; # compile-time error; outside of "our" scope
Note that "our" is never strictly required. "use strict" always allows you
to fully qualify a variable with a package name, even if you haven't
declared it with "our":
use strict;
$MyPackage::foo = 1; # legal anywhere
But doing this robs you of the compile-time checking that "use strict"
provides. So, we recommend the use of "use strict" and "our" for package
variables.
The second type of variable is a lexical variable. These are created with
the "my" statement. Unlike package variables, lexicals do not have an entry
in a package symbol table. lexical variables also have a lexical scope: they
have an existence only from the point of declaration until the end of the
innermost enclosing block. This makes them similar to "auto" or stack-based
variables in other languages. (Actually, the situation is more complex than
that; file-scoped lexicals have essentially global lifetime, and if a global
reference is taken to a block-scoped lexical, that value can persist beyond
the lexical scope, unlike in languages like C).
Anyway, you generally want to use the most restrictive scope appropriate for
your variables, in order to formalize the interfaces between your program's
parts and minimize the use of side effects through global variables. That is
why "my" variables are generally recommended over package variables.
There are some cases where you need package variables. For example, only
package variables can be exported through the Exporter.pm mechanism. Since
we always recommend the use of "use strict", you need to use "our" to
declare those variables. (However, note that *importing* a symbol via the
"use Package qw(list)" mechanism declares the symbols for the purposes of
"use strict". "our" only needs to be used in the module that exports the
symbols.)
In Summary:
Available since Perl 5, 'my' is a way to declare:
* non-package variables, that are
* private,
* new,
* non-global variables,
* separate from any package; so that the variable
* cannot be accessed in the form of $package_name::variable.
On the other hand, 'our' variables are:
* package variables, and thus automatically
* global variables,
* definitely not private,
* nor are they necessarily new; and they
* can be accessed outside the package (or lexical scope) with the qualified namespace, as $package_name::variable.
Declaring a variable with 'our' allows you to predeclare variables in order to use them under "use strict" without getting typo warnings or compile-time errors. Since Perl 5.6, it has replaced the obsolete 'use vars', which was only file-scoped, and not lexically scoped as is 'our'.
For example, the formal, qualified name for variable $x inside package main is $main::x. Declaring 'our $x' allows you to use the bare $x variable without penalty (i.e., without a resulting error), in the scope of the declaration, when the script uses 'use strict' or 'use strict "vars"'. The scope might be one, or two, or more packages, or one small block.
===================================================================================
The PerlMonks and PerlDoc links from cartman and Olafur are a great reference - below is my crack at a summary:
my variables are lexically scoped within a single block defined by {} or within the same file if not in {}s. They are not accessible from packages/subroutines defined outside of the same lexical scope / block.
our variables are scoped within a package/file and accessible from any code that uses/requires that package/file - name conflicts are resolved between packages by prepending the appropriate namespace.
Just to round it out, local variables are "dynamically" scoped, differing from my variables in that they are also accessible from subroutines called within the same block.
==================================================================================
Coping with scooping(Namespaces)
is a document which has a good overview of Perl scoping rules, but it's old enough to have discussion about "our".
=================================================================================
perldoc is also a good reference.
=================================================================================
one can also refer to
=================================================================================
Perl has two kinds of variables. The first kind are global variables (also
called "package" variables or "symbol table" variables). These variables a)
have a name in a package's symbol table, and b) have a lifetime equal to the
duration of your process (Notwithstanding Perl's "local" statement, which
adds a twist. But save that for another discussion.)
You refer to a package variable like this:
$MyPackage::foo = 1;
This assigns to a scalar, $foo, in the "MyPackage" package. You don't have
to declare such a variable; it is created automatically simply by your
having used it's name.
Perl has a "package" statement, which allows you to define a default package
to be used when you don't explicitly specify one. So the following is
equivalent to what's above:
package MyPackage;
$foo = 1;
(If no package statement has been issued, the default package is "main").
But that raises a problem. Since global variables are created automatically,
it's easy to introduce bugs into your program by making typos in variable
names.
That's where "use strict" comes in. "use strict" (which should *always* be
used in your programs), requires you to pre-declare package variables that
you plan to use without a package name. Consider:
package MyPackage;
use strict;
$foo = 1; # compile-time error: $foo not defined
"our" is a declaration that introduces a package variable. So instead you
write:
package MyPackage;
use strict;
our $foo;
$foo = 1; # OK; $foo has been declared
You can combine the declaration and assignment in one step:
our $foo = 1;
Now if you accidentally misspell $foo as $fooo later in your program, Perl
will raise a compile-time error.
You can think of "our" as a license to use the variable without its package
name under "use strict".
"our" obeys lexical scoping rules. That is to say, your "license" is good
from the point you issue the "our", until the end of the innermost enclosing
block, eval, or file. Consider:
use strict;
{
our $foo;
$foo = 1; # OK, "our" declaration is in force
} # block ends, "our" declaration ends
$foo = 2; # compile-time error; outside of "our" scope
Note that "our" is never strictly required. "use strict" always allows you
to fully qualify a variable with a package name, even if you haven't
declared it with "our":
use strict;
$MyPackage::foo = 1; # legal anywhere
But doing this robs you of the compile-time checking that "use strict"
provides. So, we recommend the use of "use strict" and "our" for package
variables.
The second type of variable is a lexical variable. These are created with
the "my" statement. Unlike package variables, lexicals do not have an entry
in a package symbol table. lexical variables also have a lexical scope: they
have an existence only from the point of declaration until the end of the
innermost enclosing block. This makes them similar to "auto" or stack-based
variables in other languages. (Actually, the situation is more complex than
that; file-scoped lexicals have essentially global lifetime, and if a global
reference is taken to a block-scoped lexical, that value can persist beyond
the lexical scope, unlike in languages like C).
Anyway, you generally want to use the most restrictive scope appropriate for
your variables, in order to formalize the interfaces between your program's
parts and minimize the use of side effects through global variables. That is
why "my" variables are generally recommended over package variables.
There are some cases where you need package variables. For example, only
package variables can be exported through the Exporter.pm mechanism. Since
we always recommend the use of "use strict", you need to use "our" to
declare those variables. (However, note that *importing* a symbol via the
"use Package qw(list)" mechanism declares the symbols for the purposes of
"use strict". "our" only needs to be used in the module that exports the
symbols.)
Tuesday, April 21, 2009
Parsing HTML in Perl
# Load the file into a tree
$html_tree = HTML::TreeBuilder->new;
$html_tree->;parse_file($file_name);
# Get all of the meta tags
@meta_tags = $html_tree->find('meta');
The code takes advantage of the HTML::Tree Perl module from CPAN to take the HTML file, referenced in the $file_name variable, and build a tree of the tags in memory. Once the tree is built I can use the find method to find all of the meta tags and put them into the array @meta_tags. Once I have the array I can step through them one at a time and process them as required.
It is worth noting the HTML::Tree module is dependent on the HTML::Parser module which is dependent on the HTML::Tagset module.
Following link contains
http://www.tc.umn.edu/~hause011/code/extract_from_many_excel.html
code to extract escel data.
$html_tree = HTML::TreeBuilder->new;
$html_tree->;parse_file($file_name);
# Get all of the meta tags
@meta_tags = $html_tree->find('meta');
The code takes advantage of the HTML::Tree Perl module from CPAN to take the HTML file, referenced in the $file_name variable, and build a tree of the tags in memory. Once the tree is built I can use the find method to find all of the meta tags and put them into the array @meta_tags. Once I have the array I can step through them one at a time and process them as required.
It is worth noting the HTML::Tree module is dependent on the HTML::Parser module which is dependent on the HTML::Tagset module.
Following link contains
http://www.tc.umn.edu/~hause011/code/extract_from_many_excel.html
code to extract escel data.
EXTRACTING DATA FROM TABLE using Perl
erl has a module that does this: HTML::TableExtract (http://kobesearch.cpan.org:/htdocs/HTML-TableExtract/HTML/TableExtract.html), the examples are a good start, don't forget to add "my $te" to each variable declaration when using "use strict".
Also, to download the HTML data directly you could use:
#!/usr/bin/perl
use strict;
use warnings;
use HTML::TableExtract;
use LWP::Simple;
my $html = get("http://ubuntuforums.org");
my $table = HTML::TableExtract->new;
$table->parse($html);
# Table parsed, extract the data.
Also, to download the HTML data directly you could use:
#!/usr/bin/perl
use strict;
use warnings;
use HTML::TableExtract;
use LWP::Simple;
my $html = get("http://ubuntuforums.org");
my $table = HTML::TableExtract->new;
$table->parse($html);
# Table parsed, extract the data.
open OUTPUT, "| grep 'foo' > result.txt" or die "Failure: $!";
We can then write whatever we want to the "OUTPUT" filehandle. The Unix "grep"
command will filter out any text which doesn't contain the text "foo"; any text
which DOES contain "foo" will be written to "result.txt".
Don't Use OPEN
And for programs that only return a few lines of output, use back-ticks:
my $username = `whoami` or die "Couldn't execute command: $!";
chomp($username);
print "My name is $username\n";
You can also use the "qx//" operator, which is exactly equivalent to back-ticks
except that it allows you to choose your delimiter:
# All of the following are exactly equivalent
# to the above command that uses back-ticks.
my $username = qx/whoami/ or die "Couldn't execute command: $!";
my $username = qx(whoami) or die "Couldn't execute command: $!";
my $username = qx#whoami# or die "Couldn't execute command: $!";
We can then write whatever we want to the "OUTPUT" filehandle. The Unix "grep"
command will filter out any text which doesn't contain the text "foo"; any text
which DOES contain "foo" will be written to "result.txt".
Don't Use OPEN
And for programs that only return a few lines of output, use back-ticks:
my $username = `whoami` or die "Couldn't execute command: $!";
chomp($username);
print "My name is $username\n";
You can also use the "qx//" operator, which is exactly equivalent to back-ticks
except that it allows you to choose your delimiter:
# All of the following are exactly equivalent
# to the above command that uses back-ticks.
my $username = qx/whoami/ or die "Couldn't execute command: $!";
my $username = qx(whoami) or die "Couldn't execute command: $!";
my $username = qx#whoami# or die "Couldn't execute command: $!";
COMMAND LINE ARGUMENTS
Command-Line Arguments :: @ARGV
* So how do we get command line arguments? Perl automatically stores any command line arguments into a global list called @ARGV.
* Each element in @ARGV sequentially contains the command-line arguments called with the program. You can parse these manually by hand, or use the more "sophisticated" getopt method below.
Command-Line Arguments :: Getopt::Std and Getopt::Long
* Perl provides getopt-like functionality using the packages Getopt::Std and Getopt::Long. For example:
use Getopt::Std;
getopt('oDI'); # -o, -D & -I take arg. Sets opt_* as a side effect.
getopt('oDI', \%opts); # -o, -D & -I take arg. Values in %opts
getopts('oif:'); # -o & -i are boolean flags, -f takes an argument
# Sets opt_* as a side effect.
getopts('oif:', \%opts); # options as above. Values in %opts
This example is taken from the man pages. getopt works much in the same way as getopt in C, but simpler. In the last example, getopts will take in -o, -i, -f with -f having arguments. The hash %opts contains the arguments, with the switches as the keys for the hash.
* Getopt::Long can take in switches longer than one character.
Tangent :: Using Packages/Modules
* You've probably noticed by now that we can call libraries, packages, or modules (whatever you want to call them), using the use keyword followed by the module.
* In the above example, we used the Getopt::Std package. There are tons of standard modules and even more non-standard modules. Think of these as ANSI C Standard libraries and non-standard libraries for Perl. Other packages include File::Copy, Text::ParseWords, Math::Complex, and CGI. There are many, many more. See Schwartz Pgs. 238-242, and Wall Ch. 30-32 (pgs. 831-915).
* So how do we get command line arguments? Perl automatically stores any command line arguments into a global list called @ARGV.
* Each element in @ARGV sequentially contains the command-line arguments called with the program. You can parse these manually by hand, or use the more "sophisticated" getopt method below.
Command-Line Arguments :: Getopt::Std and Getopt::Long
* Perl provides getopt-like functionality using the packages Getopt::Std and Getopt::Long. For example:
use Getopt::Std;
getopt('oDI'); # -o, -D & -I take arg. Sets opt_* as a side effect.
getopt('oDI', \%opts); # -o, -D & -I take arg. Values in %opts
getopts('oif:'); # -o & -i are boolean flags, -f takes an argument
# Sets opt_* as a side effect.
getopts('oif:', \%opts); # options as above. Values in %opts
This example is taken from the man pages. getopt works much in the same way as getopt in C, but simpler. In the last example, getopts will take in -o, -i, -f with -f having arguments. The hash %opts contains the arguments, with the switches as the keys for the hash.
* Getopt::Long can take in switches longer than one character.
Tangent :: Using Packages/Modules
* You've probably noticed by now that we can call libraries, packages, or modules (whatever you want to call them), using the use keyword followed by the module.
* In the above example, we used the Getopt::Std package. There are tons of standard modules and even more non-standard modules. Think of these as ANSI C Standard libraries and non-standard libraries for Perl. Other packages include File::Copy, Text::ParseWords, Math::Complex, and CGI. There are many, many more. See Schwartz Pgs. 238-242, and Wall Ch. 30-32 (pgs. 831-915).
File Type Test
File Input/Output :: File Tests
* For further fool-proof file Error Handling and the Misc. you can pass file tests to filehandles. To test the existence of a file you can do this for example:
$filename = "hooray.index";
if (-e $filename) {
open(outf, ">>hooray.index");
} else {
open(outf, ">>hooray-hooray.index");
}
* There are many other file tests: -T tests for ASCII file, -B tests for a Binary file, -d tests for a directory, -l tests for a symlink.
Perl provides a way to query information about a particular file also:
($dev, $ino, $mode, $nlink, $uid, $gid, $rdev, $size, $atime, $mtime,
$ctime, $blksize, $blocks) = stat ($filename);
The stat function provides all these fields about the particular file $filename. Refer to Wall Pgs. 800-801 for more information about stat. You can also get information about a file using the File::stat package:
use File::stat;
$sb = stat($filename);
print "$sb->size\n";
This would print the size of the file. More on File::stat in the Larry Wall book.
* For further fool-proof file Error Handling and the Misc. you can pass file tests to filehandles. To test the existence of a file you can do this for example:
$filename = "hooray.index";
if (-e $filename) {
open(outf, ">>hooray.index");
} else {
open(outf, ">>hooray-hooray.index");
}
* There are many other file tests: -T tests for ASCII file, -B tests for a Binary file, -d tests for a directory, -l tests for a symlink.
Perl provides a way to query information about a particular file also:
($dev, $ino, $mode, $nlink, $uid, $gid, $rdev, $size, $atime, $mtime,
$ctime, $blksize, $blocks) = stat ($filename);
The stat function provides all these fields about the particular file $filename. Refer to Wall Pgs. 800-801 for more information about stat. You can also get information about a file using the File::stat package:
use File::stat;
$sb = stat($filename);
print "$sb->size\n";
This would print the size of the file. More on File::stat in the Larry Wall book.
File Error Handling in Perl
File Input/Output :: Error Handling
What if we can get a filehandle? We should handle this case graciously by using die. For example:
open (inf, "/some/directory/file.in") || die "cannot open: $!";
So what does this do? Perl tries to open file.in OR it calls die with the string. The $! contains the most recent system error, so it will append a useful tag to the output of die. You could even make a dienice subroutine that could be more helpful. You can exit a Perl program immediately by calling exit;.
What if we can get a filehandle? We should handle this case graciously by using die. For example:
open (inf, "/some/directory/file.in") || die "cannot open: $!";
So what does this do? Perl tries to open file.in OR it calls die with the string. The $! contains the most recent system error, so it will append a useful tag to the output of die. You could even make a dienice subroutine that could be more helpful. You can exit a Perl program immediately by calling exit;.
File Handling In perl Script
Handling input and output from/to files and the Command Prompt
As previously noted, programs consist primarily of data and instructions for manipulating the data. Earlier we looked at programs where the data was included in the program code. However, programs can also manipulate data from external sources, such as text files and the terminal.
Input/Output from/to the Terminal
There are two principle ways of getting data into and out of Perl scripts: by using the terminal and by using files. The "terminal" is basically the command prompt supplied by the operating system of your computer. Any output to the terminal is known to Perl (and to most Unix-based programming languages) as STDOUT, and any input from the terminal is known as STDIN. The most common use of STDOUT is with the print function; in fact, if you do not tell "print" where to print to, it outputs to STDOUT by default. Therefore, the two statements are equivalent:
print "Hello";
print SDTOUT "Hello";
In the scripts that we will be writing in this course, we won't be using STDIN, which is mainly useful for short amounts of unstructured data (our data tends to be highly structured, using tabs, fields, etc.). However, since it is so easy to print to STDOUT, when writing short scripts many people often print to SDTOUT and redirect the output to a file. This allows them to forgo opening and writing files from within Perl (which we will look at in a moment). To redirect STDOUT to a file, use the following syntax:
perl script.pl > captured_output.txt
The > operator is not part of Perl; rather, it is part of most operating systems including Unix, Linux, Mac OS X and Windows.
Redirecting STDOUT to a file is not always desirable. For example, if you want your script to output more than one file, redirecting is not straight forward. Also, redirecting only works well when the output is plain text. MARC communications files are binary, so we should not use redirection to create them.
Input/Output from/to Files
Perl uses the following functions to open and close files (appropriately called
"open" and "close"):
open (INPUTFILE, "$input");
close (INPUTFILE);
"INPUTFILE" is called a filehandle, and is the name that Perl uses to refer to the open file. The actual name has no significance (we could have called this one CGGG6HHH), but by convention it is in upper-case characters (but doesn't have to be). The second parameter, "$input" in this case, is a variable that contains the location of the file that is to be associated with the filehandle. In you script
It is common to include error-checking code in file open and close statements, since files can have any number of problems, such as not being there (file not found) or permissions problems. The open statement above with this type of error checking is:
open (INPUTFILE, "$input") or die ("Problem with opening $input: $!");
$! is a special Perl variable that contains the last error message, which in this case will be the fatal error produced by Perl if it can't open the identified file.
You define how you want an open file to interact with your script by assigning a "mode". The three most common modes are read, overwrite, and append, signified by <, >, and >>, respectively. The mode indicators are prepended to the location of the file. For example,
open (FILE, "<$file"); # Means open $file in read mode
open (FILE, ">$file"); # Means open $file in overwrite mode
open (FILE, ">>$file"); # Means open $file in append mode
Now, to put the pieces together. If you want to read data from a file, simply open it in read mode. The contents of the file will be added to the filehandle, which you can then manipulate in various ways. We'll describe how to read a file line at a time later.
If you want to add data to a file (called "print" the data to the file), you need to open the file in either overwrite or append mode (depending on what you want to do) and then use the print function along with the filehandle you want to print to, like this:
open (OUTPUTFILE, ">$output") or die ("Problem with opening $output: $!");
print OUTPUT "Whatever you want to add to the file"; close OUTPUT;
Notice that in this example we printed to OUTPUT just like we printed to STDOUT above. STDOUT is actually a special filehandle reserved for the terminal.
It is not usually necessary to explicitly close open files, but it is a good habit to get into.
Exercise (Spreadsheet)
To illustrate how the above works in practice, we will write a spreadsheet program.
First create the spreadsheet in Jedit:
12 4 167 17 8
9 34 4 12 1
62 14 67 0 88
78 9 34 67 5
Thats five numbers on each line, separated by tabs. They don't have to be these numbers exactly.
Now let's write a new program, spreadsheet.pl, that will add up all the numbers on each line and give us separate totals.
#this is the world's simplest spreadsheet program
open (SPREADSHEET, "spreadsheet.txt")
or die ("Problem opening file: $!");
while () {
$numbers = $_;
chomp($numbers);
@numbers = split(/\t/, $numbers);
$total = 0;
foreach $number (@numbers){
$total = $total + $number;
}
print $total . "\n";
}
close (SPREADSHEET);
How it Works
As you can see, this program re-uses a lot of the same logic that we covered with hello.pl, and yet what it does is very different.
while means 'while whatever is between the brackets returns a value, do whatever is between the curly braces'. The standard way that perl reads files is one line at a time. So the instructions between the braces gets repeated for every line in the file.
As lines from the file are read into the program, perl doesn't really know what to call them. So it assigns them the variable name $_, for lack of anything more helpful. You could continue to refer to them that way, but it makes the rest of the program more readable to give the incoming lines a more descriptive variable name. So they are assigned here to the $numbers variable, using the assignment operator, =.
Other things we have not yet seen are the addition operator, +, and the split instruction. The split instruction splits data into chunks on whatever you specify as the separator, and stores the resulting values in an array. In this case, we've told split to split the line using the tab character as the separator, represented by \t.
After we've used the split instruction to populate the @numbers array, we then use foreach to run through each number in the array, adding it to the $total variable. This is an example of a nested loop (the foreach loop is nested within the while loop, which means the entire foreach loop is run for every iteration of the while loop. There is no limit as to how deeply you can nest loops - theoretically you can have loops within loops within loops ad infinitum. However, too much nesting will really slow down your script.
As previously noted, programs consist primarily of data and instructions for manipulating the data. Earlier we looked at programs where the data was included in the program code. However, programs can also manipulate data from external sources, such as text files and the terminal.
Input/Output from/to the Terminal
There are two principle ways of getting data into and out of Perl scripts: by using the terminal and by using files. The "terminal" is basically the command prompt supplied by the operating system of your computer. Any output to the terminal is known to Perl (and to most Unix-based programming languages) as STDOUT, and any input from the terminal is known as STDIN. The most common use of STDOUT is with the print function; in fact, if you do not tell "print" where to print to, it outputs to STDOUT by default. Therefore, the two statements are equivalent:
print "Hello";
print SDTOUT "Hello";
In the scripts that we will be writing in this course, we won't be using STDIN, which is mainly useful for short amounts of unstructured data (our data tends to be highly structured, using tabs, fields, etc.). However, since it is so easy to print to STDOUT, when writing short scripts many people often print to SDTOUT and redirect the output to a file. This allows them to forgo opening and writing files from within Perl (which we will look at in a moment). To redirect STDOUT to a file, use the following syntax:
perl script.pl > captured_output.txt
The > operator is not part of Perl; rather, it is part of most operating systems including Unix, Linux, Mac OS X and Windows.
Redirecting STDOUT to a file is not always desirable. For example, if you want your script to output more than one file, redirecting is not straight forward. Also, redirecting only works well when the output is plain text. MARC communications files are binary, so we should not use redirection to create them.
Input/Output from/to Files
Perl uses the following functions to open and close files (appropriately called
"open" and "close"):
open (INPUTFILE, "$input");
close (INPUTFILE);
"INPUTFILE" is called a filehandle, and is the name that Perl uses to refer to the open file. The actual name has no significance (we could have called this one CGGG6HHH), but by convention it is in upper-case characters (but doesn't have to be). The second parameter, "$input" in this case, is a variable that contains the location of the file that is to be associated with the filehandle. In you script
It is common to include error-checking code in file open and close statements, since files can have any number of problems, such as not being there (file not found) or permissions problems. The open statement above with this type of error checking is:
open (INPUTFILE, "$input") or die ("Problem with opening $input: $!");
$! is a special Perl variable that contains the last error message, which in this case will be the fatal error produced by Perl if it can't open the identified file.
You define how you want an open file to interact with your script by assigning a "mode". The three most common modes are read, overwrite, and append, signified by <, >, and >>, respectively. The mode indicators are prepended to the location of the file. For example,
open (FILE, "<$file"); # Means open $file in read mode
open (FILE, ">$file"); # Means open $file in overwrite mode
open (FILE, ">>$file"); # Means open $file in append mode
Now, to put the pieces together. If you want to read data from a file, simply open it in read mode. The contents of the file will be added to the filehandle, which you can then manipulate in various ways. We'll describe how to read a file line at a time later.
If you want to add data to a file (called "print" the data to the file), you need to open the file in either overwrite or append mode (depending on what you want to do) and then use the print function along with the filehandle you want to print to, like this:
open (OUTPUTFILE, ">$output") or die ("Problem with opening $output: $!");
print OUTPUT "Whatever you want to add to the file"; close OUTPUT;
Notice that in this example we printed to OUTPUT just like we printed to STDOUT above. STDOUT is actually a special filehandle reserved for the terminal.
It is not usually necessary to explicitly close open files, but it is a good habit to get into.
Exercise (Spreadsheet)
To illustrate how the above works in practice, we will write a spreadsheet program.
First create the spreadsheet in Jedit:
12 4 167 17 8
9 34 4 12 1
62 14 67 0 88
78 9 34 67 5
Thats five numbers on each line, separated by tabs. They don't have to be these numbers exactly.
Now let's write a new program, spreadsheet.pl, that will add up all the numbers on each line and give us separate totals.
#this is the world's simplest spreadsheet program
open (SPREADSHEET, "spreadsheet.txt")
or die ("Problem opening file: $!");
while (
$numbers = $_;
chomp($numbers);
@numbers = split(/\t/, $numbers);
$total = 0;
foreach $number (@numbers){
$total = $total + $number;
}
print $total . "\n";
}
close (SPREADSHEET);
How it Works
As you can see, this program re-uses a lot of the same logic that we covered with hello.pl, and yet what it does is very different.
while means 'while whatever is between the brackets returns a value, do whatever is between the curly braces'. The standard way that perl reads files is one line at a time. So the instructions between the braces gets repeated for every line in the file.
As lines from the file are read into the program, perl doesn't really know what to call them. So it assigns them the variable name $_, for lack of anything more helpful. You could continue to refer to them that way, but it makes the rest of the program more readable to give the incoming lines a more descriptive variable name. So they are assigned here to the $numbers variable, using the assignment operator, =.
Other things we have not yet seen are the addition operator, +, and the split instruction. The split instruction splits data into chunks on whatever you specify as the separator, and stores the resulting values in an array. In this case, we've told split to split the line using the tab character as the separator, represented by \t.
After we've used the split instruction to populate the @numbers array, we then use foreach to run through each number in the array, adding it to the $total variable. This is an example of a nested loop (the foreach loop is nested within the while loop, which means the entire foreach loop is run for every iteration of the while loop. There is no limit as to how deeply you can nest loops - theoretically you can have loops within loops within loops ad infinitum. However, too much nesting will really slow down your script.
Monday, March 16, 2009
Information on %~dp0
This macro is used to get the path of batch file.
It doesn't matter from where you are calling batch file it will return the path where the batch file is stored.
So if you put the following in a batch file, no matter what directory you are in when you run it, it will print the directory the batch file is in, and do a directory listing.
e.g. :
echo Batch file path is %~dp0
dir %~dp0
It doesn't matter from where you are calling batch file it will return the path where the batch file is stored.
So if you put the following in a batch file, no matter what directory you are in when you run it, it will print the directory the batch file is in, and do a directory listing.
e.g. :
echo Batch file path is %~dp0
dir %~dp0
Tips on Creating Batch Files
The PATH variable can be set in two ways:
SET PATH=c:\bat;c:\dosor:
PATH c:\bat;c:\dosIn the first case, using SET, the PATH variable is set to c:\bat;c:\dos, in lower case, as specified.
In the second case, using PATH, the PATH variable is set to C:\BAT;C:\DOS, in upper case, no matter how it was specified.
%cd% is available either to a batch file or at the command prompt and expands to the drive letter and path of the current directory (which can change e.g. by using the CD command)
%~dp0 is only available within a batch file and expands to the drive letter and path in which that batch file is located (which cannot change). It is obtained from %0 which is the batch file's name.
An experiment like the following shows the difference
Here is D:\dirshow.bat:
Code:
@echo off
echo this is %%cd%% %cd%
echo this is %%~dp0 %~dp0
Run it from C:\ and this is what you see
Code:
C:\>D:\dirshow.bat
this is %cd% C:\
this is %~dp0 D:\
Sunday, March 15, 2009
Contact Us
Please leave your valuable comments here... If you have any suggestions or if you want me to put a article on any topic of your choice please leave a comment here... alternatively you can send me a mail at mailme.blogadda[at]gmail.com
Enjoy the Programming..
Enjoy the Programming..
Subscribe to:
Posts (Atom)